Como funciona Tableau? La pregunta es orientada a ver como esta su arquitectura, de esa forma podemos visualizar, planificar, estimar como se comportará bajo ciertas condiciones. Según la explicación que tenemos de Rush Shan es un aplicativo basado en el lightweight Apache Web Server, con esta primera pista podemos imaginarnos ya, como se comportaría, o al menos tener indicios de ello. Comparado con Glashfish, o JBoss, apache es ligero, sencillo y comodo según la comunidad OpenSource. Apache es básicamente un Web Server y Servlet Container, es decir no viene con todas la aplicaciones que estan definidad en el JavaEE, como por ejemplo EJB container, JPA, pero eso no es limitante, ya que todas ellas se pueden agregar por aparte al Apache, como OpenJPA, Hibernate, OpenEJB, y otras más. Además Existe TomEE+ que es una versión que integra todas características de JavaEE.
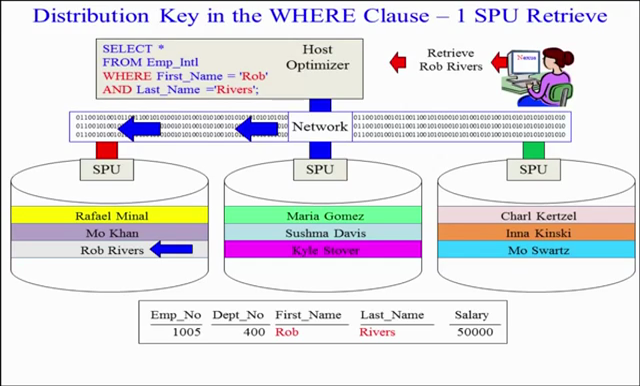
En las laminas de abajo que salen del webinario de Rush Shan, se muestran los elementos que integran la aplicación de Tableau, su funcionalidad y responsabilidades. Se puede tener acceso a servicios del modulo VizQL Server para incorporalos como gráficas a aplicaciones foráneas de usuarios. el VizQL Server es muy demandante de CPU y memoria. Una limitación es que el modulo Data Engine que adquiere los datos de una base de datos, está limitado a solo dos nodos, Esto es si se distrubuyen en más servidores, solo dos nodos podrán fungir como Data Engine en la arquitectura.
Tableau tiene un repositorio interno basado en PostgreSQL, donde guarda datos funcionales propios como usuarios, grupos....
Se muestran 3 configuraciones básicas de la arquitectura que se puede tener en Tableau, Single Node, 3 Nodes, y 5 nodes, en las cuales de consideran aspectos de Alta Disponibilidad y Recuperación de desastres.
Introduction to Tableau Architecture https://www.youtube.com/watch?v=v8_iLBdGlm4
Planing and Architecting Tableau https://www.youtube.com/watch?v=CpyrCryHr8c